Building Diphone
database (cont)
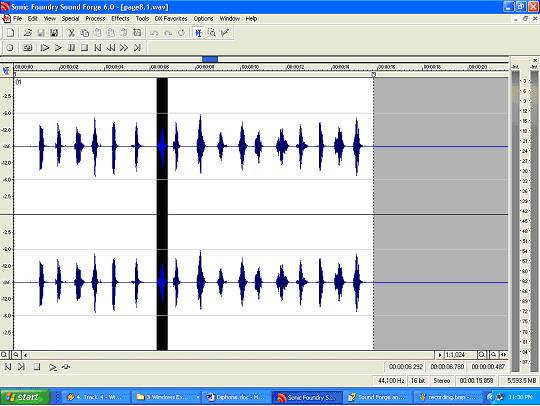
Fig. Collecting diphones from audio data files.
Segmentation/Alignment
For segmentation and
alignment we use manual or hand labeling process. For
this we used Sourge Forge and EMU level. This is a lengthy
and error prone process. But as there are no pre built
diphone database for Bangla we cant use the DTW or any
other automated process for this. If there exists a
pre built synthesizer for Bangla then it would become
a much easier task for us.
Quality control
After the manual alignment and labeling is finished,
the results are visually inspected by either random
sample, or by checking every one, using display tools
such as emulabel [4]. In collecting these diphone sets
we have noted that the quality of labelling has improved
as we typically use the previous set (previous recorded
voice) as the prompts. Of course this is the same voice
delivered (mostly) in the same style thus later versions
have not required full checking and sampling and targeting
problems alone has been sufficient.
Extracting pitchmarks and pitch-synchronous
parameters
Once the recordings are made and are labelled, building
the diphone synthesizer itself is mostly automatic.
Our first stage is to extract the pitchmarks from the
EGG signal, but as there are no electroglottograph was
used at recording time we can not use the pitchmark
program that is part of the Edinburgh Speech Tools.
But we can extract the pitchmarks form the waveform
files directly, but this is typically not as good from
the EGG signal. For all voice sections of the speech,
we position the pitchmarks at the peak of the pitch
period. For non-voiced sections, we introduce a ``fake''
or pitch mark evenly spaced through those sections.
As our signal techniques for pitch and duration modification
depend of pitch synchronous analysis, getting the pitch
marks right is very important to the final quality of
the synthesizer.
Although we try hard to ensure that the audio quality
remains constant throughout the whole recording, it
is unusual for the whole set to be done, perfectly,
in a single sitting, and we have found that slight differences
in power occur between different sittings, due to position
of the microphone as well as the speaker delivering
with different vocal effort. To combat this, we include
a simple power normalization phase. As different phones
have different inherent power can cannot simply normalize
everything; therefore, we calculate the mean RMS power
over all vowels in each nonsense word, then find the
mean over all the files, and calculate a modification
factor for each word that in the normalization.
After power normalization, we extract LPC parameters
pitch synchronously.
Diphone index
As diphones run from mid of one phone to mid of another,
we need to know exactly where that ``mid'' is. For supported
languages, it is already known where the diphone boundary
is in existing diphone databases, so when we synthesize
the prompts, the accompanying labels include both the
phone boundary positions, as well as the diphone boundaries.
Although midway between phone boundaries may be the
most appropriate join point for vowels, it almost certainly
is not for stops, where the closure part of the phone
is by far a better place to join. Diphone boundaries
(marked as ``DB'') are also often the part requiring
correction. A Diphone index file looks like the following
-
EST_File index
DataType ascii
NumEntries 1586
EST_Header_End
#-# bd_2108 0.1075 0.11 0.1375
ro:-# bd_2085 0.011 0.141 0.293
A-# bd_2090 0.188662 0.355578 0.522449
ro-# bd_2084 0.006 0.165 0.337
h-# bd_2083 0.004 0.193 0.3896
s-# bd_2082 0.012 0.268 0.547
sh-# bd_2081 0.000 0.281 0.562
From the labels, we build a diphone index automatically,
which can be used by Festival to synthesize waveforms.
Two basic methods are offered first: so-called ``separate-mode,''
where the diphones are selected from each LPC and residual
file on demand, and ``group-mode,'' where we can collect
just the diphone parts and put them into a single large
file. The first of this is used in the initial debugging
stage. The second stage is used for distribution of
complete voices, as it is both more compact and quicker
to access.
A final voice consist of not just a diphone set, but
also the front end of the TTS system including text
analysis, lexicons and prosodic models. These, in contrast,
although difficult in themselves, are much smaller that
the diphone set, and for Bangla we can use the predefined
modules for English as start up and modify them later
to best suit Bangla. But using the built intonation
and other modules for Bangla serves as a good resource
in testing phases.
Even when the speaker is an expert in phonetics and
diphone synthesis, we know it is still very easy to
make phonetic mistakes in recording. The vowel-vowel
transitions are notably difficult to produce. They are
relatively rare in normal speech but of course as we
are collecting complete coverage we need instances of
all examples. We have also noted that there are some
transitions are particularly difficult to reliably produce,
even when we are keenly aware of the trouble spot.
|



